
- 분류 전체보기 (213)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 정보처리기사 실기 개념요약
- 프로그래머스
- 국비
- MySQL
- Flutter
- 정처기 개념요약
- 스파르타내일배움캠프
- 개발자스터디
- 컴퓨터개론
- java
- 내일배움캠프
- 스파르타코딩클럽
- Python
- 자바
- 중심사회
- 개인공부
- wil
- 소프트웨어
- til
- 99클럽
- 운영체제
- 정처기 실기 개념요약
- 스파르타내일배움캠프WIL
- 컴퓨터구조론 5판
- 백준
- 부트캠프
- 코딩테스트
- 99일지
- 스파르타내일배움캠프TIL
- 항해
- Today
- Total
컴공생의 발자취
[내일배움캠프 51일차 TIL] JPQL과 QueryDSL 본문
2024.06.28.(금)
오늘의 진도 : JPA 심화 완강 까지...
뭐가 많아도 너무 많다...
오늘의 학습, 면담, 오늘의 회고 이렇게 3개의 큰 틀로 나누어 정리할 것이다.
💡 오늘의 학습 키워드
- JPA 심화 4주차 -
ORM
Repository vs JpaRepository
RawJPA
Entity 코드 정리
Cascade
orphanRemoval
Cascade.REMOVE vs orphanRemoval
Fetch
JpaREpository
페이지 반환 타입
정렬
JPQL
- JPA 심화 5주차 -
QueryDSL
@DynamicInsert & DynamicUpdate
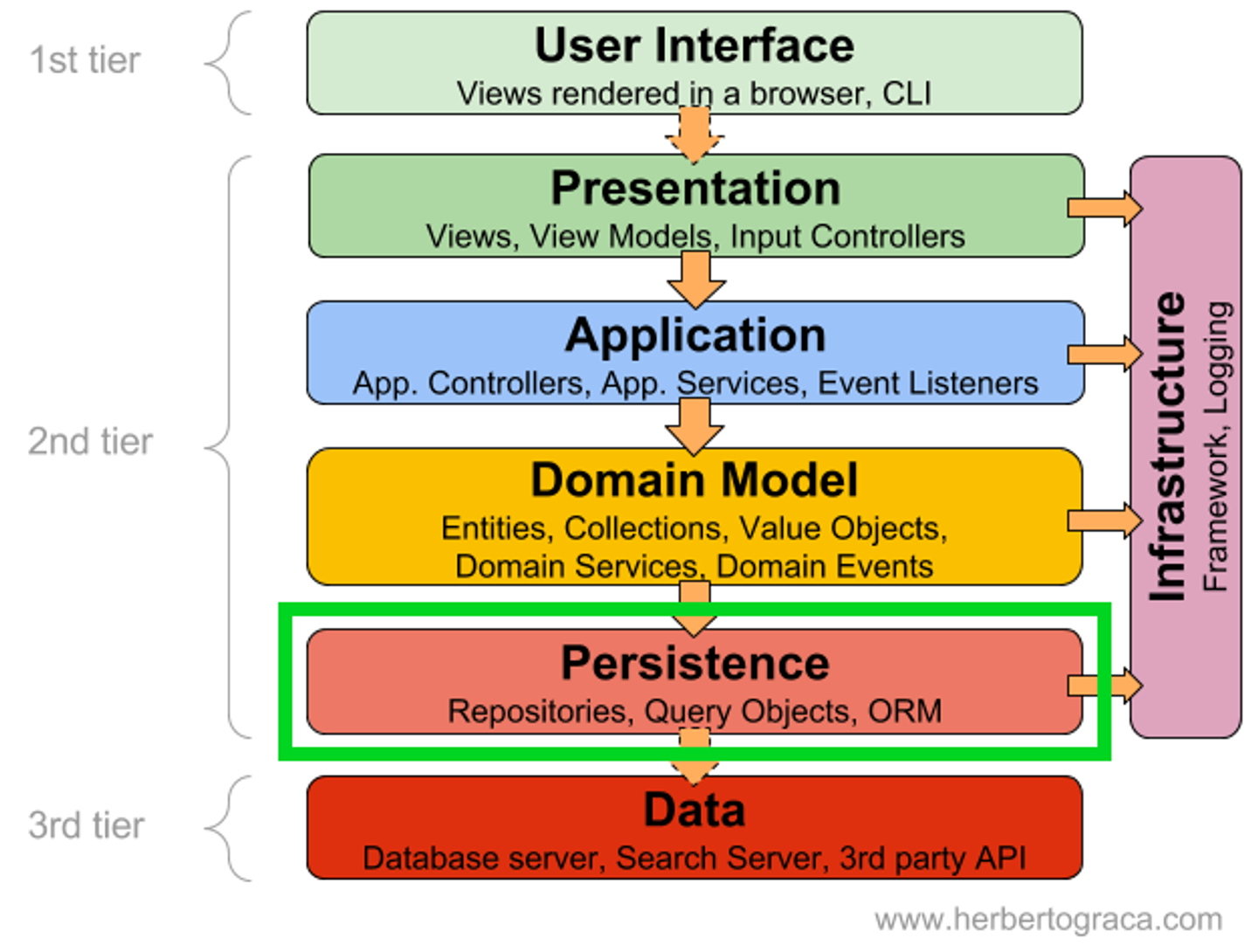
ORM (Object Relation Mapping)
: 테이블을 하나의 객체(Object)와 대응시켜 버린다.
* 탄생 이유
- QueryMapper의 DB 의존성 및 중복 쿼리 문제로 탄생
- 객체지향(Object)을 관계형 데이터베이스(Relation)에 매핑(Mapping) 한다는 건 정말 많은 난관
* 문제점
- 상속의 문제
- 객체 : 객체간에 멤버변수나 상속관계를 맺을 수 있다.
- RDB : 테이블들은 상속관계가 없고 모두 독립적으로 존재한다.
- 💁♂️ 해결방법 : 매핑정보에 상속정보를 넣어준다. (@OneToMany, @ManyToOne)
- 관계 문제
- 객체 : 참조를 통해 관계를 가지며 방향을 가진다. (다대다 관계도 있음)
- RDB : 외래키(FK)를 설정하여 Join 으로 조회시에만 참조가 가능하다. (즉, 다대다는 매핑 테이블 필요)
- 💁♂️ 해결방법 : 매핑정보에 방향정보를 넣어준다. (@JoinColumn, @MappedBy)
- 탐색 문제
- 객체 : 참조를 통해 다른 객체로 순차적 탐색이 가능하며 콜렉션도 순회한다.
- RDB : 탐색시 참조하는 만큼 추가 쿼리나, Join 이 발생하여 비효율적이다.
- 💁♂️ 해결방법 : 매핑/조회 정보로 참조탐색 시점을 관리한다.(@FetchType, fetchJoin())
- 밀도 문제
- 객체 : 멤버 객체크기가 매우 클 수 있다.
- RDB : 기본 데이터 타입만 존재한다.
- 💁♂️ 해결방법 : 크기가 큰 멤버 객체는 테이블을 분리하여 상속으로 처리한다. (@embedded)
- 식별성 문제
- 객체 : 객체의 hashCode 또는 정의한 equals() 메소드를 통해 식별
- RDB : PK 로만 식별
- 💁♂️ 해결방법 : PK 를 객체 Id로 설정하고 EntityManager는 해당 값으로 객체를 식별하여 관리 한다.(@Id,@GeneratedValue )
* 해결책
영속성 컨텍스트(1차 캐시)를 활용한 쓰기 지연
* JPA에서는 재사용하기 위한 임시저장소를 영속성 컨텍스트라고 한다.
- 영속성 이란?
- 데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.
- 영속성을 갖지 않으면 데이터는 메모리에서만 존재하게 되고 프로그램이 종료되면 해당 데이터는 모두 사라지게 된다.
- 그래서 우리는 데이터를 파일이나 DB에 영구 저장함으로써 데이터에 영속성을 부여한다.
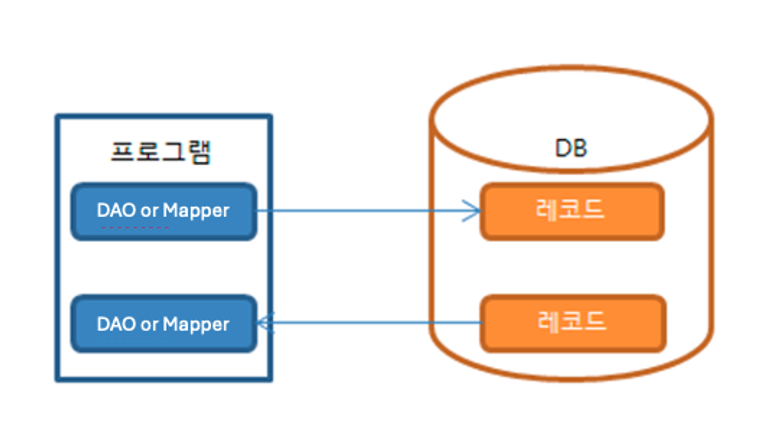
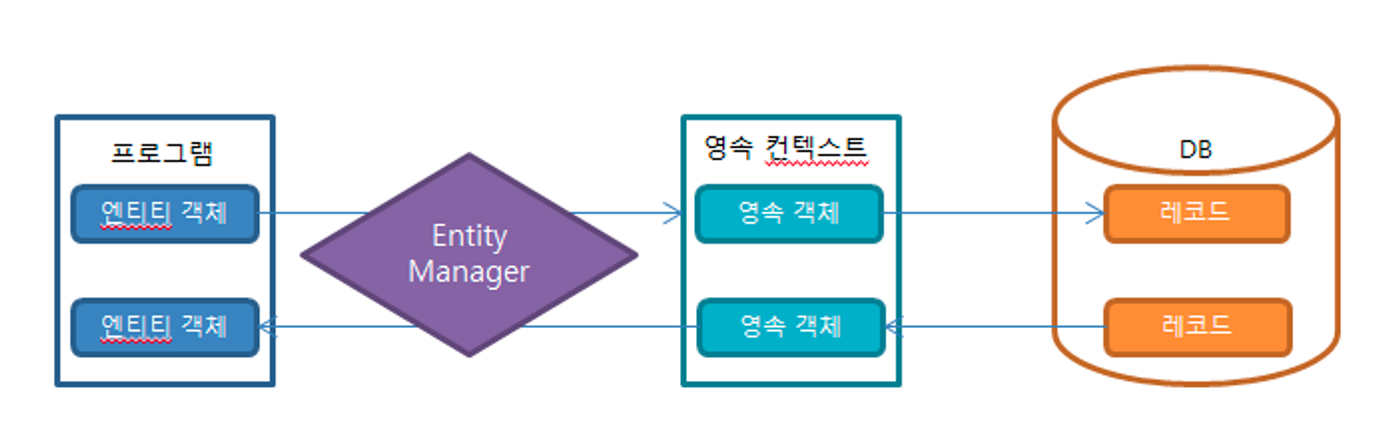
- 영속성 4가지 상태 ( 비영속 > 영속 > 준영속 | 삭제)
- 쓰기 지연이 발생하는 시점
- flush() 동작이 발생하기 전까지 최적화한다.
- flush() 동작으로 전송된 쿼리는 더이상 쿼리 최적화는 되지 않고, 이후 commit()으로 반영만 가능하다.
- 쓰기 지연 효과
- 여러개의 객체를 생성할 경우 모아서 한번에 쿼리를 전송한다.
- 영속성 상태의 객체가 생성 및 수정이 여러번 일어나더라도 해당 트랜잭션 종료시 쿼리는 1번만 전송될 수 있다.
- 영속성 상태에서 객체가 생성되었다 삭제되었다면 실제 DB에는 아무 동작이 전송되지 않을 수 있다.
- 즉, 여러가지 동작이 많이 발생하더라도 쿼리는 트랜잭션당 최적화 되어 최소쿼리만 날라가게된다.
- 💁♂️ 키 생성전략이 generationType.IDENTITY 로 설정 되어있는 경우 생성쿼리는 쓰기지연이 발생하지 못한다.
- why? 단일 쿼리로 수행함으로써 외부 트랜잭션에 의한 중복키 생성을 방지하여 단일키를 보장한다.
Repository vs JpaRepository
: ORM을 사용하는 가장 쉬운 방법
Repository vs JpaRepository
- 기존 Repository
- @Repository 을 클래스에 붙인다.
- @Component 어노테이션을 포함하고 있어서 앱 실행시 생성 후 Bean으로 등록된다.
- 앞서배운 Repository 기본 기능만 가진 구현체가 생성된다. (DB별 예외처리 등)
- 새로운 JpaRepository
- JpaRepository<Entity,ID> 인터페이스를 인터페이스에 extends 붙인다.
- @NotRepositoryBean 된 ****상위 인터페이스들의 기능을 포함한 구현체가 프로그래밍된다. (@NotRepositoryBean = 빈생성 막음 →상속받으면 생성돼서 사용가능)
- JpaRepository (마스터 셰프): 데이터 액세스를 위한 핵심 기능의 종합적인 요리책(기능) 을 제공합니다.
- @NotRepositoryBean 인터페이스 (셰프): 각 인터페이스는 특정 데이터 액세스 방법을 제공하는 전문적인 기술 또는 레시피를 나타냅니다.
- JpaRepository 상속: 마스터 셰프의 요리책과 셰프의 전문성을 얻습니다.
- SpringDataJpa 에 의해 엔티티의 CRUD, 페이징, 정렬 기능 메소드들을 가진 빈이 등록된다. (상위 인터페이스들의 기능)
- @NotRepositoryBean 된 ****상위 인터페이스들의 기능을 포함한 구현체가 프로그래밍된다. (@NotRepositoryBean = 빈생성 막음 →상속받으면 생성돼서 사용가능)
- JpaRepository<Entity,ID> 인터페이스를 인터페이스에 extends 붙인다.
Raw JPA
* 테이블 매핑 기능
- @Entity
- @Table
- @Id
- @GeneratedValue
- @Column
- @Temporal
- @Transient
* 필드 타입 매핑 기능
- 기본 타입
- @Column
- @Enumerated
- Composite Value 타입
- @Embeddable
- @Embedded
- @AttributeOverrides
- @AttributeOverride
- Collection Value 타입
- 기본 타입의 콜렉션 : @ElementCollection
- Composite 타입의 콜렉션 : @ElementCollection
Entity 코드 정리
* IntelliJ Live Template 사용 추천
- Settings > Editor > Live Templates
- Template text:
/**
* 컬럼 - 연관관계 컬럼을 제외한 컬럼을 정의합니다.
*/
/**
* 생성자 - 약속된 형태로만 생성가능하도록 합니다.
*/
/**
* 연관관계 - Foreign Key 값을 따로 컬럼으로 정의하지 않고 연관 관계로 정의합니다.
*/
/**
* 연관관계 편의 메소드 - 반대쪽에는 연관관계 편의 메소드가 없도록 주의합니다.
*/
/**
* 서비스 메소드 - 외부에서 엔티티를 수정할 메소드를 정의합니다. (단일 책임을 가지도록 주의합니다.)
*/
Cascade (영속성 전이)
- 사용 위치
- 연관관계의 주인 반대편 - 부모 엔티티(다대일에서 일)
- 즉, @OneToMany 가 있는 쪽 또는 @OneToOne 도 가능
- 예를들어, 게시글과 첨부파일이라면 일에 해당하는 게시글에 설정한다.
- 사용 조건
- 양쪽 엔티티의 라이프사이클이 동일하거나 비슷해야한다.
- 예를들어, 게시글이 삭제되면 첨부파일도 같이 삭제 되어야 한다.
- 대상 엔티티로의 영속성 전이는 현재 엔티티에서만 전이 되어야 한다. (다른곳에서 또 걸면 안됨)
- 예를들어, 첨부파일을 게시글이 아닌 다른곳에서 영속성 전이를 하면 안된다.
- 양쪽 엔티티의 라이프사이클이 동일하거나 비슷해야한다.
- 옵션 종류
- ALL : 전체 상태 전이
- PERSIST : 저장 상태 전이
- REMOVE : 삭제 상태 전이
- MERGE : 업데이트 상태 전이
- REFERESH : 갱신 상태 전이
- DETACH : 비영속성 상태 전이
orphanRemoval (고아 객제 제거)
- 사용 위치
- @OneToMany 또는 @OneToOne 에서 사용 - 부모 엔티티
- 사용법
- Cascade.REMOVE 와 비슷한 용도로 삭제를 전파하는데 쓰인다.
- 부모 객체에서 리스트 요소삭제를 했을경우 해당 자식 객체는 매핑정보가 없어지므로 대신 삭제해준다.
- 요건 DB 에서는 절대 알 수 없는 행동이다. (부모가 자식의 손을 놓고 버리고 간 고아 객체)
- 옵션
- true
- false
Cascade.REMOVE vs orphanRemoval
Cascade.REMOVE의 경우 일에 해당하는 부모 엔티티를 em.remove를 통해 직접 삭제할 때,그 아래에 있는 다에 해당하는 자식 엔티티들이 삭제되는 것입니다.
orphanRemoval=true는 위 케이스도 포함하며,일에 해당하는 부모 엔티티의 리스트에서 요소를 삭제하기만 해도 해당 다에 해당하는 자식 엔티티가 delete되는 기능까지 포함하고 있다고 이해하시면 됩니다.
즉, orphanRemoval=true 는 리스트 요소로써의 영속성 전이도 해준다는 뜻
* 영속성 전이 최강 조합 : orphanRemoval=true + Cascade.ALL
위 2개를 함께 설정하면 자식 엔티티의 라이프 사이클이 부모 엔티티와 동일해지며, 직접 자식 엔티티의 생명주기를 관리할 수 있게 되므로 자식 엔티티의 Repository 조차 없어도 된다. (따라서, 매핑 테이블에서 많이 쓰임)
Fetch (조회시점)
- 사용 위치
- Entity 에 FetchType 으로 설정할 수 있다.
- @ElementCollection, @ManyToMany, @OneToMany, @ManyToOne, @OneToOne
- Query 수행시 fetch Join 을 통해서 LAZY 인 경우도 즉시 불러올 수 있다.
- Entity 에 FetchType 으로 설정할 수 있다.
- 사용법
- 기본 LAZY를 설정한 뒤에 필요할때만 fetch Join 을 수행한다.
- 항상 같이 쓰이는 연관관계 일 경우만 EAGER 를 설정한다.
- 옵션(FetchType)
- EAGER : 즉시 로딩 (부모 조회 시 자식도 같이 조회)
- LAZY : 지연 로딩 (자식은 필요할때 따로 조회)
JpaRepository
* 프로그래밍되어 제공되는 쿼리명 규칙
리턴타입 {접두어}{도입부}By{프로퍼티 표현식}(조건식)[(And|Or){프로퍼티 표현식}(조건식)](OrderBy{프로퍼티}Asc|Desc) (매개변수...)
| 접두어 | Find, Get, Query, Count, ... |
| 도입부 | Distinct, First(N), Top(N) |
| 프로퍼티 표현식 | Person.Address.ZipCode => find(Person)ByAddress_ZipCode(...) |
| 조건식 | IgnoreCase, Between, LessThan, GreaterThan, Like, Contains, ... |
| 정렬 조건 | OrderBy{프로퍼티}Asc|Desc |
| 리턴 타입 | E, Optional<E>, List<E>, Page<E>, Slice<E>, Stream<E> |
| 매개변수 | Pageable, Sort |
- 쿼리 실습 코드
// 기본
List<User> findByNameAndPassword(String name, String password);
// distinct (중복제거)
List<User> findDistinctUserByNameOrPassword(String name, String password);
List<User> findUserDistinctByNameOrPassword(String name, String password);
// ignoring case (대소문자 무시)
List<User> findByNameIgnoreCase(String name);
List<User> findByNameAndPasswordAllIgnoreCase(String name, String password);
// 정렬
List<Person> findByNameOrderByNameAsc(String name);
List<Person> findByNameOrderByNameDesc(String name);
// 페이징
Page<User> findByName(String name, Pageable pageable); // Page 는 카운트쿼리 수행됨
Slice<User> findByName(String name, Pageable pageable); // Slice 는 카운트쿼리 수행안됨
List<User> findByName(String name, Sort sort);
List<User> findByName(String name, Pageable pageable);
// 스트림 (stream 다쓴후 자원 해제 해줘야하므로 try with resource 사용추천)
Stream<User> readAllByNameNotNull();
* JpaRepository 효율적으로 사용하는 방법
Optional 제거하기
Spring Data JPA의 findByXX 메서드는 기본적으로 Optional을 반환한다. 이로 인해 비즈니스 로직에서 Optional 처리를 위한 추가적인 작업이 필요하게 되는데, 이럴 때 default 메서드를 활용하면 이 문제를 우아하게 해결할 수 있다.
public interface UserRepository extends JpaRepository<User, Long> {
// Default 메소드를 사용하여 findById의 Optional을 내부적으로 처리
default User findUserById(Long id) {
return findById(id).orElseThrow(() -> new DataNotFoundException("User not found with id: " + id));
}
}
메서드명 간소화하기
Spring Data JPA를 사용하다 보면 복잡한 쿼리 때문에 메서드명이 길어져 가독성을 해치는 경우가 있다. 이럴 때도 default 메서드를 활용하면 긴 메서드명을 간결하고 명확하게 표현할 수 있다.
public interface ProductRepository extends JpaRepository<Product, Long> {
// 기존의 긴 쿼리 메소드
List<Product> findAllByCategoryAndPriceGreaterThanEqualAndPriceLessThanEqualOrderByPriceAsc(String category, BigDecimal minPrice, BigDecimal maxPrice);
// Default 메소드를 사용하여 간결한 메소드명 제공
default List<Product> findProductsByCategoryAndPriceRange(String category, BigDecimal minPrice, BigDecimal maxPrice) {
return findAllByCategoryAndPriceGreaterThanEqualAndPriceLessThanEqualOrderByPriceAsc(category, minPrice, maxPrice);
}
}
비즈니스 로직 통합
여러 기본 제공 메서드를 하나의 고차 작업으로 결합할 수도 있다. 다만 Spring Data JPA의 Repository는 Data Access Layer의 일부로, 데이터베이스와의 상호작용만을 담당하는 것이 일반적이기 때문에 이 부분은 서비스 레이어에서 처리하는 것이 일반적이다.
public interface UserRepository extends JpaRepository<User, Long> {
// 사용자 ID로 사용자를 찾고, 존재할 경우 연락처 정보를 업데이트하는 메소드
default void updateUserContact(Long userId, String newContact) {
findById(userId).ifPresent(user -> {
user.setContact(newContact);
save(user);
});
}
}
페이지 반환 타입
Page<T> 타입
- 게시판 형태의 페이징에서 사용된다.
- 전체 요소 갯수도 함께 조회한다. (totalElements)
- 응답은 위와 동일
Slice<T> 타입
- 더보기 형태의 페이징에서 사용된다.
- 전체 요소 갯수 대신 offset 필드로 조회할 수 있다.
- 따라서 count 쿼리가 발생되지 않고 limit+1 조회를 한다. (offset 은 성능이 안좋아서 현업에서 안씁니다)
List<T> 타입
- 전체 목록보기 형태의 페이징에서 사용된다.
- 기본 타입으로 count 조회가 발생하지 않는다.
정렬
컬럼 값으로 정렬하기
- Sort 클래스를 사용한다.
Sort sort1 = Sort.by("name").descending(); // 내림차순
Sort sort2 = Sort.by("password").ascending(); // 오름차순
Sort sortAll = sort1.and(sort2); // 2개이상 다중정렬도 가능하다
Pageable pageable = PageRequest.of(0, 10, sortAll); // pageable 생성시 추가
컬럼이 아닌값으로 정렬하기
- @Query 사용시 Alias(쿼리에서 as 로 지정한 문구) 를 기준으로 정렬할 수 있다.
Sort sort1 = Sort.by("name").descending(); // 내림차순
Sort sort2 = Sort.by("password").ascending(); // 오름차순
Sort sortAll = sort1.and(sort2); // 2개이상 다중정렬도 가능하다
Pageable pageable = PageRequest.of(0, 10, sortAll); // pageable 생성시 추가
SQL 함수를 사용해서 정렬하기
- JpaSort 를 사용해서 쿼리 함수를 기준으로 정렬할 수 있다.
// 이렇게 해당 user_password 를 기준으로 정렬할 수 있다.
List<User> users = findByUsername("user", Sort.by("user_password"));
JPQL (Java Persistence Query Language)
Table 이 아닌 Entity(객체) 기준으로 작성하는 쿼리를 JPQL 이라고 하며
이를 사용할 수 있도록 EntityManger 또는 @Query 구현체를 통해 JPQL 쿼리를 사용할 수 있다.
- SQL : Table 명으로 쿼리짤때 쓰이는 언어 (쓰이는곳. JDBC, SQL Mapper)
- JPQL : Entity 명으로 쿼리짤때 쓰이는 언어 (쓰이는곳. JPQL, QueryDSL)
QueryDSL
- Entity 의 매핑정보를 활용하여 쿼리에 적합하도록 **쿼리 전용 클래스(Q클래스)**로 재구성해주는 기술 입니다.
- 여기에 JPAQueryFactory 을 통한 Q클래스를 활용할 수 있는 기능들을 제공합니다.
- 그럼, JPAQueryFactory 는 뭘까요?
- 재구성한 Q클래스를 통해 문자열이 아닌 객체 또는 함수로 쿼리를 작성하고 실행하게 해주는 기술 입니다.
@PersistenceContext
EntityManager em;
public List<User> selectUserByUsernameAndPassword(String username, String password){
JPAQueryFactory jqf = new JPAQueryFactory(em);
QUser user = QUser.user;
List<Person> userList = jpf
.selectFrom(user)
.where(person.username.eq(username)
.and(person.password.eq(password))
.fetch();
return userList;
}
@DynamicInsert & @DynamicUpdate
: 이 어노테이션을 엔티티에 적용하게 되면 Insert & Update 쿼리를 날릴 때 null 인 값은 제외하고 쿼리문이 만들어집니다.
- 적용 방법
- Entity에 어노테이션을 붙여주면 끝!
@DynamicInsert
// @DynamicUpdate
public class User {
...
}
- 적용 전
Hibernate:
insert
into
users
(password, username, id)
values
(?, ?, ?) // 141ms 소요
- 적용 후
Hibernate:
insert
into
users
(username, id)
values
(?, ?) // 133ms 소요
면담(질문)
- Q : 지금부터라도 내가 가고 싶은 회사들의 기준을 정해놓아야 할텐데 어떻게 정하나요?
- 갈 수 있는 회사 : 필수 + 우대
- 대기업 : 공고 필수 자격 어떻게 할지?
-> 코테, 기술질문(다른기업)
오늘의 회고
- 12시간 중 얼마나 몰입했는가?
원래 JPA 강의 다 듣고 AWS까지 다 들으려고 했는데..
노트북 대여한 것이 와서 오후는 계속 세팅하느라 시간을 다 써버렸다ㅠ
심지어 맥북인지라.. 내가 쓰던 단축키가 안되는 것도 있고 뭔가 기능이 많아서 어려워..
일주일은 지나야 적응을 좀 할 듯 싶다..
그리고 세팅하고 나서 저녁에라도 AWS 강의를 들었는데 정리를 못해서 아직 안 올렸다!
- 오늘의 생각
원래 TIL이라도 금요일 저녁에 올렸어야 하는데..
불금이라고 놀고 토요일은 코딩테스트한다고 심신미약으로 손도 안 댔닼ㅋㅋ
이제라도 올려야지..
- 내일 학습할 것은 무엇인지
월요일이니까..!
학습이라기 보단 이제 슬슬 내가 가고 싶은 곳을 정하고 목표를 정해야겠다.
그러고 코딩테스트 준비를 조금 더 신경 써야 할 것 같고 정처기 실기.. 또 준비><
아무튼 회사를 정해야 공고를 보고 최종 프로젝트에서 내가 해보아야할 기술이 무엇인지 알 수 있을 것 같다.
'🤝 활동 > 내배캠TIL' 카테고리의 다른 글
| [내일배움캠프 53일차 TIL] Docker Image와 Container (0) | 2024.07.02 |
|---|---|
| [내일배움캠프 52일차 TIL] AWS (0) | 2024.07.02 |
| [내일배움캠프 50일차 TIL] 데이터베이스(H2, JDBC 드라이버, Query Mapper)및 MyBatis (0) | 2024.06.27 |
| [내일배움캠프 49일차 TIL] AWS 계정 생성 및 IAM (0) | 2024.06.27 |
| [내일배움캠프 48일차 TIL] 아웃소싱 프로젝트 (feat. KPT 회고) (1) | 2024.06.25 |



