2.1 인출 사이클의 마이크로 연산 : t0 = MAR ← PC
t1 = MBR ← M[MAR], PC ← PC + 1
t2 = IR ← MBR
실행 사이클의 마이크로 연산 : t0 = MAR ← IR(addr)
t1 = MBR ← M[MAR]
t2 = AC ← MBR
따라서 총 6 클록이 소요되고 주기가 0.5ns 이므로 명령어를 인출하고 실행하는데 걸리는 시간은 총 6 × 0.5ns = 3ns이다.
2.2
(1)


(2) ‘SUB 301’명령어가 실행 되는 중이므로 PC는 202, AC는 0004, IR은 6301, SP는 0999가 저장되어 있다. 여기서 인터럽트 요구가 들어온다면
① PC의 값이 SP가 가진 값의 주소에 저장되고
② PC에는 인터럽트 서비스 루틴의 시작 주소가 저장되며
③ SP에는 SP – 1 값이 저장된다.
따라서 PC는 450, AC는 0004, IR은 6301, SP는 0998이 저장된다.
2.3 인터럽트 사이클이 종료되면 SP의 값은 0998이다. 따라서 AC의 값은 기억장치의 998번지에 저장되며 SP의 값은 SP – 1 즉, 0997이 저장된다.
2.4 CPU가 인터럽트 서비스 루틴 처음 부분에 ‘인터럽트 불가능(interrupt disabled)’ 명령어(DI 명령어)를 실행하고 인터럽트 서비스 루틴의 끝 부분에 ‘인터럽트 가능(interrupt enabled)’ 명령어(EI 명령어)를 실행한다.
2.5 첫 번째 명령어를 실행하는 데에는 4 클록 주기가 걸리고, 그 다음 명령어부터는 1 클록 주기가 걸린다. 따라서, 1000개의 명령어를 모두 실행하려면 4 + 999 = 1003 클록 주기가 걸린다.
클록 주파수가 2 GHz이므로 1 클록 주기는 1 / (2GHz) = 1 / (2 × 109Hz) = 0.5 × 10-9 = 0.5ns이다. 따라서 1000개의 명령어를 모두 실행하는데 소요되는 시간은 1003 × 0.5ns = 501.5ns이다.
2.6 클록 주파수가 4 GHz이므로 1 클록 주기는 1 / (4 GHz) = 0.25ns이다.
12 단계 파이프라인을 사용하는 경우, 1000개의 명령어를 실행하려면 총 1011 클록 주기가 걸리고 그 시간은 1011 × 0.25ns = 252.75ns이다.
파이프라인을 사용하지 않는 경우, 명령어 1개당 12단계를 거쳐야 하므로 1000개의 명령어를 실행하려면 총 12 × 1000 = 12000 클록 주기가 걸리고 그 시간은 12000 × 0.25ns = 3000ns이다.
따라서 속도 향상(Sp) = 3000ns / 252.75ns ≒ 11.86배이고 효율(E) = 11.86 / 12 ≒ 0.98이다.
2.7
(1) 클록 주파수가 2 GHz이므로 1 클록 주기는 1 / (2 GHz) = 0.5ns이다.
N = 10일 때, 걸리는 시간은 0.5ns × {5 + (10 –
1)} = 7ns이다.N = 100일 때, 걸리는 시간은 0.5ns × {5 + (100 –
1)} = 52ns이다.N = 1000일 때, 걸리는 시간은 0.5ns × {5 + (1000 – 1)} = 502ns이다.
N = 10000일 때, 걸리는 시간은 0.5ns × {5 + (10000 – 1)} = 5002ns이다.
(2) N = 10일 때, Sp = (2.5ns × 10) / 7ns ≒ 3.57배
N = 100일 때, Sp = (2.5ns × 100) / 52ns ≒
4.81배N = 1000일 때, Sp = (2.5ns × 1000) / 502ns ≒
4.98배N = 10000일 때, Sp = (2.5ns × 10000) / 5002ns ≒ 5.00배
(3)

2.8
(1) 공통 클록의 주파수가 1 GHz이므로 1 클록 주기는 1 / (1 GHz) = 1ns이다.파이프라인을 이용하지 않으면, 100개의 명령어는 2 × 100 = 200 클록 주기, 400개의 명령어는 3 × 400 = 1200 클록 주기, 나머지 500개의 명령어는 4 ×
500 = 2000 클록 주기가 필요하다.따라서 프로그램을 처리하는 데 걸리는 시간은 (200 + 1200 + 2000) × 1ns = 3400ns이다.
(2) 4 단계 파이프라인을 사용하므로 1000개의 명령어를 처리하는데 걸리는 클록 주기는 {4 + (1000 – 1)} = 1003이고 걸리는 시간은 1003 × 1ns = 1003ns이다.
(3) 속도 향상(Sp) = 3400ns / 1003ns ≒ 3.39배이고, 효율(E) = 속도 향상/파이프라인 단계의 수 = 3.39 / 4 = 0.8475이다.
2.9 어떤 CPU에서 명령어 실행 과정이 네 개의 사이클들로 이루어진다고 하자. 첫 번째 사이클의 처리에 걸리는 시간이 0.5ns, 두 번째와 세 번째 사이클은 1.0ns씩, 그리고 마지막 사이클은 0.75ns가 각각 걸린다고 하자.
(1) 한 명령어를 실행하는 데 걸리는 시간은 모든 사이클을 처리하는데 걸리는 시간과 같으므로 0.5ns + 1.0ns + 1.0ns + 0.75ns = 3.25ns이다.
(2) 각 파이프라인의 단계들을 처리하는데 걸리는 시간은 가장 늦게 처리되는 사이클의 시간을 기준으로 한다. 따라서 한 단계를 처리하는데 걸리는 시간은 1ns이다. 그러므로 1클록 주기는 4ns이고,
주파수는 1 / (4ns) = 1 / (4 × 10-9sec) = 0.25 × 109 = 0.25 GHz이다.
(3) 1개의 명령어를 실행하는데 걸리는 시간은 1클록 주기이므로 4ns이다. 따라서 파이프라인을 사용하지 않을 때의 시간 3.25ns보다 0.75ns만큼 느리다.
(4) 100개의 명령어를 실행하는데 걸리는 시간은 파이프라인을 사용하지 않을 경우, 3.25ns × 100 = 325ns이고 파이프라인을 사용할 경우 1ns × {4 + (100 – 1)} = 103ns이다. 따라서 파이프라인을 사용함으로써 얻게 되는 속도 향상(Sp) = 325ns / 103ns ≒ 3.16배이다.
2.10
(1) 각 파이프라인의 단계들을 처리하는데 걸리는 시간은 가장 늦게 처리되는 사이클의 시간을 기준으로 한다. 따라서 클록의 주파수는 1 / (400ps) = 1 / (400 × 10-12sec) = 10 / (4 × 10-9sec) = 2.5 GHz이다.
(2) 1000개의 명령어를 순차적으로 실행하는데 걸리는 시간은 400ps × {4 + (1000 – 1) = 401200ps = 401.2ns이다.
(3) 성능을 높이는데 도움이 되지 않는다. 왜냐하면 각 파이프라인의 단계들을 처리하는데 걸리는 시간은 가장 늦게 처리되는 사이클의 시간을 기준으로 하기 때문에 OF단계의 처리 시간을 단축시켜야만 전체 파이프라인의 성능을 높이는데 도움이 된다.
(4) 가장 늦게 처리되는 사이클의 시간이 EX단계로 바뀌었으므로, 파이프라인의 성능이 나빠진다. 또한 명령어 1000개를 실행하는 경우 전체 소요 시간은 500ps × {4 + (1000 – 1) = 501500ps = 501.5ns이고, (2)번 결과 401.2ns에 비해 501.5ns / 401.2ns = 1.25배 느려진다.
2.11 다섯 번째 명령어가 분기 명령어 이므로 실행 단계에서 분기가 발생한다. 그러므로 12개의 명령어를 실행하는 데 걸리는 시간은 4단계 파이프라인으로 5개의 명령어의 실행시간 + 7개 명령어의 실행 시간과 같다 따라서 총 {4 + (5 – 1)} + {4 + (7 – 1)} = 18사이클이 걸린다.
2.12
(1) 5 + (100 – 1) = 104 클록 주기만큼 걸린다.
(2) 실행되는 명령어들 간의 데이터 의존성이 존재하지 않으므로 유휴(idle) 상태에 들어가지 않게 된다. 따라서 5 + {(100 / 2) – 1} = 54클록 주기만큼 걸리고, 속도 향상은 104 / 54 ≒ 1.93배이다.
2.13 동시에 처리되는 명령어들 간의 데이터 의존성이 존재하지 않을 경우, 슈퍼스칼라 프로세서를 사용하는 경우 사용하지 않는 경우 보다 4 × 5 = 20배의 속도 향상을 얻을 수 있다.
2.14 듀얼-코어 프로세서에서 슈퍼스칼라의 명령어 파이프라인에 비하여 각 CPU 코어의 독립성이 더 높아 프로그램 실행을 독립적으로 수행하며, 필요한 경우에만 공유 캐시를 통하여 정보를 교환하기 때문이다. 그리고 프로그램 내에서 여러 개의 태스크 프로그램들이 독립적으로 처리될 수 있다면 듀얼-코어 및 멀티-코어 프로세서가 내부 CPU 코어 수만큼의 성능 향상을 얻을 수 있다.
2.15 ‘CALL 56FE’ 명령어가 두 단어 길이이므로 주기억장치는 단어단위(16비트)로 지정된다.
| PC | SP | |
| CALL 명령어가 실행되기 전 | 215B | FFFC |
| CALL 명령어가 실행된 후 | 56FE | FFFB |
| 서브루틴으로부터 복귀한 후 | 215D | FFFC |
| 다시 한 번 RET 명령어가 실행된 후 | 123A | FFFD |
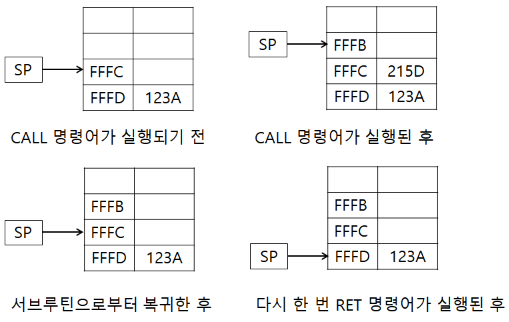
(1) CALL 명령어가 실행되기 전 PC의 값은 CALL 명령어가 저장된 주소를 가리켜야 한다.
(2) CALL 명령어가 실행된 후 오퍼랜드 필드에 저장된 ‘56FE’ 번지로 PC 값이 변경되며 기존에 저장되어 있던 다음 주소 215B + 2 = 215D의 값은 스택에 저장된다. 또한 SP의 값은 FFFC – 1 = FFCB로 변경한다. (여기서 주기억장치가 단어단위로 지정되므로 –1을 한다.)
(3) 서브루틴으로부터 복귀한 후에는 스택의 값에 저장된 주소를 다시 PC에 저장하고 SP의 값은 FFFB + 1 = FFFC로 변경한다.
(4) 다시 한 번 RET 명령어가 되었으므로 스택의 FFFD에 저장된 값인 ‘123A’를 PC에 저장하고 SP의 값은 FFFC + 1 = FFFD로 변경한다.
2.16
(1)
| 명령어 | 연산 내용 |
| LOAD A | AC ← M[A] |
| ADD B | AC ← AC + M[B] |
| STOR P | M[P] ← AC |
| LOAD E | AC ← M[E] |
| MUL F | AC ← AC × M[F] |
| STOR Q | M[Q] ← AC |
| LOAD G | AC ← M[G] |
| MUL H | AC ← AC × M[H] |
| STOR R | M[R] ← AC |
| LOAD D | AC ← M[D] |
| SUB Q | AC ← AC – M[Q] |
| ADD R | AC ← AC + M[R] |
| STOR S | M[S] <- AC |
| LOAD P | AC ← M[P] |
| DIV S | AC ← AC / S |
| STOR X | M[X] ← AC |
(2)
| 명령어 | 연산 내용 |
| MOV R1, A | R1 ← M[A] |
| ADD R1, B | R1 ← R1 + M[B] |
| MOV R2, E | R2 ← M[E] |
| MUL R2, F | R2 ← RE × M[F] |
| MOV R3, G | R3 ← M[G] |
| MUL R3, H | R3 ← R3 × M[H] |
| MOV R4, D | R4 ← M[D] |
| SUB R4, R2 | R4 ← R4 - R2 |
| ADD R4, R3 | R4 ← R4 + R3 |
| DIV R1, R4 | R1 ← R1 / R4 |
| MOV X, R1 | M[X] ← R1 |
(3)
| 명령어 | 연산 내용 |
| ADD R1, A, B | R1 ← M[A] + M[B] |
| MUL R2, E, F | R2 ← M[E] × M[F] |
| MUL R3, G, H | R3 ← M[G] × M[H] |
| SUB R4, D, R2 | R4 ← M[D] – R2 |
| ADD R5, R4, R3 | R5 ← R4 + R3 |
| DIV X, R1, R5 | M[X] ← R1 / R5 |
2.17
| 명령어 | 연산 내용 |
| PUSH A | TOS ← M[A] |
| PUSH B | TOS ← M[B] |
| ADD | TOS ← (TOS + 1) + TOS |
| PUSH C | TOS ← M[C] |
| PUSH D | TOS ← M[D] |
| SUB | TOS ← (TOS + 1) – TOS |
| MUL | TOS ← (TOS + 1) × TOS |
| POP X | M[X] ←TOS |
2.18
(1) A B + C – D – E +
(2) A B + C D - × E +
(3) A B × C D × + E -
(4) A B – C D – E × F / G / × E ×
2.19
(1) 16-비트 명령어에서 6비트가 연산 코드 필드이므로 오퍼랜드 필드는 10비트이다. 직접 주소지정 방식이므로 210개의 주소가 지정 될 수 있고, 단어(16비트) 단위로 주소가 지정되므로 기억장치의 용량은 210 × 16비트 = 214비트 = 211바이트 = 2MByte이다.
(2) 2의 보수로 표현되는 데이터가 저장되므로 -29 ~ (29-1) 사이의 데이터가 저장된다.
2.20
(1) 128가지 = 27의 연산들을 수행하므로 연산 코드 필드는 7비트, 내부 레지스터의 수가 16개 = 24 오퍼랜드1은 4비트, 나머지 오퍼랜드2는 32 – 7 – 4 = 21비트로 이루어진다.
(2) 21비트의 데이터가 2의 보수로 저장되므로 -220 ~ (220 – 1) 사이의 값이 저장된다.
(3) 레지스터의 개수가 16개, 레지스터의 길이가 32비트이고 레지스터 간접 주소지정 방식을 사용하므로 기억장치는 24 × 232 = 236개의 주소가 지정될 수 있고, 기억장치 주소가 바이트 단위로 지정되므로 기억장치의 용량은 236 × 1 바이트 = 26 × 1GByte = 64 GByte이다.
2.21 모든 명령어는 인출이 되어야 실행할 수 있으므로 최소 1번의 기억장치에 액세스가 필요하다.
(1) 인출 : 1, 실행 : 0
(2) 인출 : 1, 실행 : 0
(3) 인출 : 1, 실행 : 2
(4) 인출 : 1, 실행 : 1
2.22
(1) 명령어 레지스터 필드에 1이 저장되어 있고, 레지스터 주소지정 방식을 사용하므로 R1에 저장되어 있는 데이터 203이 사용된다.
(2) 레지스터 간접 주소지정 방식을 사용하므로 레지스터 R1의 내용이 유효 주소가 되므로 기억장치 203번지에 저장된 데이터 4457이 사용된다.
2.23
(1) 간접 주소 지정방식은 오퍼랜드가 가리키는 기억장치의 내용을 유효주소로 사용하는 방식이다. 그러므로 X1이 유효주소가 되어 X2를 가리키므로 (X1) = X2이다..
(2) 인덱스 주소지정 방식은 인덱스 레지스터의 내용과 명령어 내 오퍼랜드(변위)를 더하여 유효주소를 결정한다. 따라서 X1과 X3를 더한 값이 X2를 가리키므로 X1 + X3 = X2이다.
2.24
(1) 직접 주소지정 방식은 명령어 내 오퍼랜드 필드의 값을 유효주소로 사용하므로 X2의 값이 유효주소로 사용되므로 EA = X2이다.
(2) 간접 주소 지정방식은 오퍼랜드가 가리키는 기억장치의 내용을 유효주소로 사용하는 방식이다. 따라서 X2의 값인 X3가 유효주소가 된다. 따라서 EA = X3이다.
(3) 상대 주소지정 방식은 프로그램 카운터(PC)의 내용과 명령어 내 오퍼랜드(변위)를 더하여 유효주소로 사용하는 방식이다. 그러므로 프로그램 카운터의 내용인 X1과 명령어의 주소 필드 내용 X2를 더한 값이 유효주소이므로 EA = X1 + X2이다.
(4) 인덱스 주소지정 방식은 인덱스 레지스터의 내용과 명령어 내 오퍼랜드(변위)를 더하여 유효주소를 결정한다. 따라서 명령어의 주소 필드 내용 X2와 인덱스 레지스터의 내용 X4의 값을 더한 값이 유효주소이므로 EA = X2 + X4이다.
2.25 기억장치가 단어-단위로 주소가 지정되므로 명령어가 인출되는 경우 PC에는 PC 값에 +1한 값을 저장한다. 또한 상대 주소지정 방식을 사용하는 주소지정 방식이므로 X1 = X1 + X2가 저장되게 된다. 따라서 X1 = (454 + 1) – 25 = 430 값이 저장된다.
2.26
(1) 명령어의 길이가 32비트이고 기억장치의 주소가 바이트 단위로 지정되므로 명령어가 인출되는 경우 PC에는 PC 값에 +4한 값을 저장한다. 따라서 분기 명령어가 실행되면 254로 바뀌게 되고 284번지로 분기되려면 상대 주소지정 방식을 사용하기 때문에 30이 명령어의 주소필드에 저장되어야 한다. 또한 주소필드는 명령어 길이 32비트에서 연산 코드 10비트를 뺀 22비트이기 때문에 주소필드에 저장되는 값은 00 0000 0000 0000 0001 1110이다.
(2) (1)번과 마찬가지로 254번지에서 232번지로 분기해야 하므로 -22가 명령어의 주소 필드에 저장되어야 한다. 또한 값이 음수이므로 22에 2의 보수로 변환해야 하므로 주소필드에 저장되는 값은 11 1111 1111 1111 1110 1100이다.
2.27 기억장치 200번지부터 데이터 배열이 저장되어 있으므로 명령어의 오퍼랜드 필드에는 200이 저장되어야 한다. 또한 200번지부터 시작하므로 인덱스 레지스터의 값은 0부터 1씩 증가하므로 12번째 데이터 요소를 인출하기 위해서는 11이 저장되어야 한다.
2.28 레지스터-간접 주소지정 방식의 유효주소는 EA = (R)이고, 인덱스 주소지정 방식의 유효주소는 EA = A + (IX) (A는 명령어의 주소필드에 저장된 값)이므로 A의 값이 0일 경우, 유효 주소가 같아진다.
'📖 이론 > 컴퓨터구조론' 카테고리의 다른 글
| 컴퓨터 구조론 5판 6장 연습 문제 정답 (0) | 2023.06.06 |
|---|---|
| 컴퓨터 구조론 5판 5장 연습 문제 정답 (0) | 2023.06.06 |
| 컴퓨터 구조론 5판 4장 연습 문제 정답 (1) | 2023.06.06 |
| 컴퓨터 구조론 5판 3장 연습 문제 정답 (1) | 2023.06.06 |
| 컴퓨터 구조론 5판 1장 연습 문제 정답 (0) | 2023.03.14 |

